Issue, No.8 (December 2018)
Restructing of the LIS and LWS Databases
We are pleased to announce that LIS is currently working on an ambitious restructuring of the LIS and LWS Databases. Two major factors motivated the timing and content of this update: (1) The recognition that our current variable lists include a level of detail which, unfortunately, is not available in many of the datasets that we acquire, limiting users’ capacity to address comparative questions across large numbers of countries. (2) Increasing demand by the research community for lengthy over-time microdata series, while covering an increasing number of countries.
The main objective of this project is to raise the quality and ease-of-use of our harmonised microdata, by providing more standardised content across the national files. In practice, this means that the revised LIS and LWS variable templates will include fewer variables, but will offer a higher degree of comparability in the reduced sets of variables.
The main elements of this redesign can be summarised as follows:
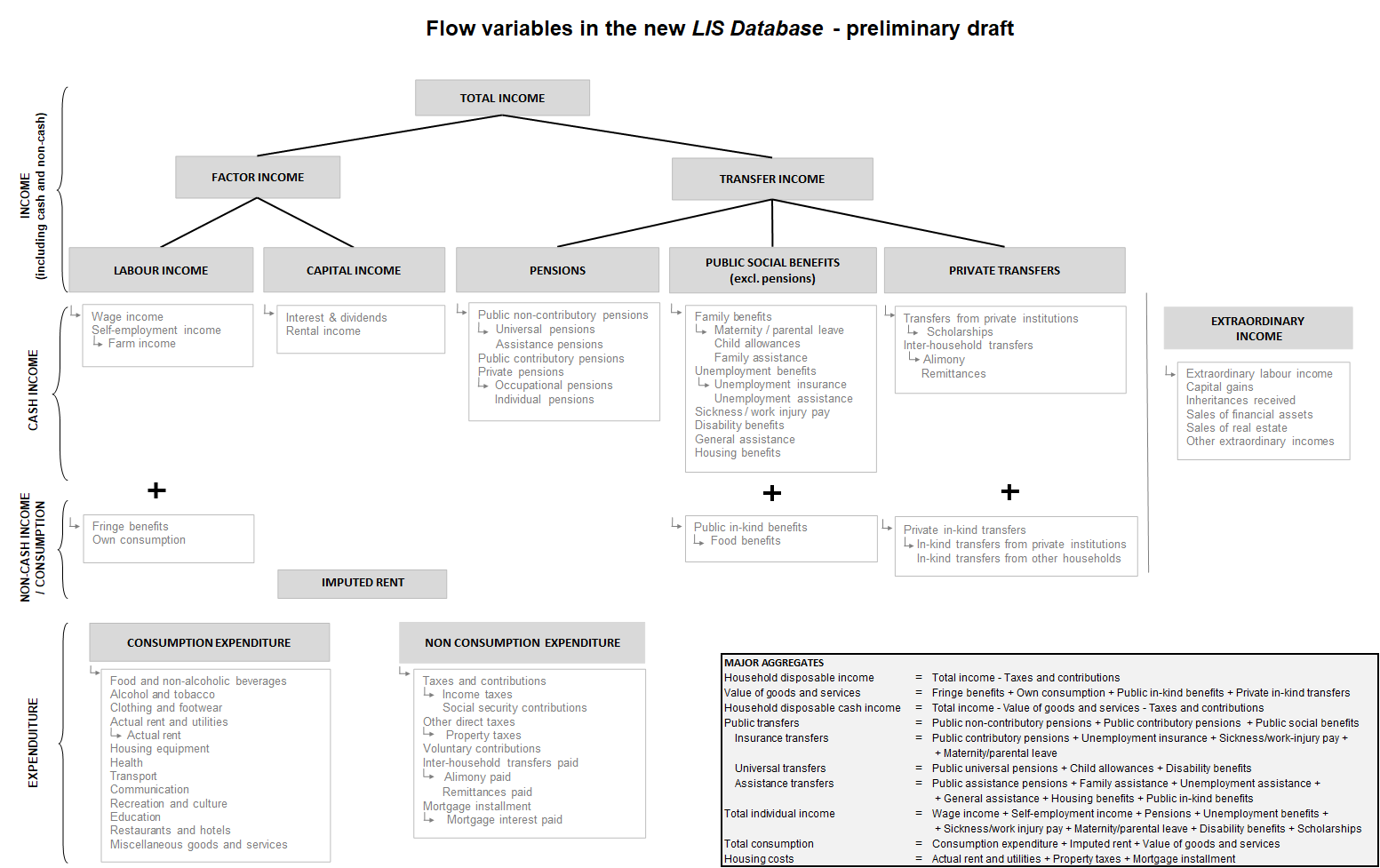
- Full restructuring of the income and expenditure variables, with the result being simpler disaggregation trees, coupled with a corresponding renaming of variables. See the schematic below for a first look at the new income and expenditure variables.
- Simplification of the information on labour force status and employment intensity.
- Removal of a number of detailed country-specific variables, coupled with the introduction of more ready-to-use dummy variables.
- Addition of two standardised education variables: highest education (at the level of the first-digit ISCED classification) and years of education. The more detailed ISCED classification will allow users to better distinguish education tracks that vary within and across countries.
How will these changes affect the work of LIS and LWS microdata users?
The LIS data team is now transforming the entire existing LIS and LWS Databases from the current into the revised format. The revised version of the two databases will be launched in March 2019. After that date, new LIS and LWS datasets will be introduced in the new data structure. Pre-revised versions of the LIS and LWS datasets will continue to be accessible through LISSY, for a period of time, to enable users to complete ongoing projects. We anticipate that this restructuring of the microdata will be accompanied by an overhaul of our documentation system (METIS) during the course of 2019.
We are confident that our data users — both new and experienced — will benefit substantially from this restructuring. In addition to increasing the quality of the harmonised data, the simplified structure will allow us, ultimately, to increase the pace at which we add more countries and more years. Our expansion plans include two priorities: adding more middle- and possibly low-income countries, and providing annual data series when possible.